








Study cohort and outcomes: Sweden
From 2010 to 2016, we gathered 441,614 ECGs from Region Halland, a public health system in Sweden. (Just to note, twelve patients in the area chose not to participate in the research, so their ECGs aren’t included.) These were linked to death certificates and electronic health records to track all patient interactions with Sweden’s national health system.51 The ECGs were collected at a rate of 500 Hz and retrieved from a Philips IntelliSpace system. The ethical review board of Lund University approved this research (protocol 2016/517 and amendment 2024-02316-02).
Prior to analysis, we implemented strict random splits to prevent overfitting (you can see a CONSORT-style diagram in the Supplementary Information section). We created a data lockbox by randomly selecting 40% of the patients and all their ECGs. This lockbox was kept untouched during model development and peer review until the manuscript was provisionally accepted. The remaining 60% was divided at the patient level, with half for training and half for validation, and used for the initial submission. Once the manuscript was provisionally accepted, we retrained the model using the 60% of data (262,554 ECGs from 75,157 patients) and applied this model unmodified to generate predictions for the lockbox data (179,060 ECGs from 51,481 patients). The findings are included here. Supplementary Information outlines changes between the original submission and the current version. Notably, model performance improved with a larger training set (for instance, AUC increased from 0.837 to 0.872), giving us more confidence about overfitting.
We analyze ECGs individually, considering risk variations over time for each patient and accounting for correlations by clustering standard errors by patient. This seems more suitable than just selecting one ECG per patient, which can reduce sample size and possibly skew results (like, choosing the most recent ECG could bias results toward those who survived initial ECGs). All statistical tests are two-sided.
Our main focus is on sudden cardiac death occurring within a year after ECGs, except for those from the final year of our dataset (2016). While we lost access to death certificates post-2016, we can still track comprehensive electronic health records from 2017 onward, which show if a clinical encounter occurred. If such an encounter happens within a year post-ECG, we regard the outcome as absent rather than missing. As a result, only 12,969 out of 247,286 training set ECG records and 6,446 out of 125,987 lockbox ECGs are censored and excluded from outcome evaluation metrics (though they’re still used selectively in training, as noted in the Supplementary Information).
Our definition of sudden cardiac death relies on death certificates and standard epidemiological criteria24: deaths (i) from cardiac or ambiguous causes, and (ii) that occurred outside a hospital or within the first 24 hours of hospital admission. More details can be found in the Supplementary Information. There are various methods to define sudden cardiac death, each with its pros and cons. An ideal definition might be ‘arrhythmic death,’ which means death that could be halted by defibrillation (like VF/VT). Of course, to measure this accurately, you’d need continuous ECG monitoring, which isn’t common. Most studies use other data sources like diagnosis codes from death certificates, reviewing medical charts, or autopsy findings. Detailed reviews and autopsies provide more specific data about arrhythmic deaths, but these are only feasible for smaller groups; meanwhile, death certificates offer broader data but less detail.
Numerous studies have examined how well our primary definition aligns with in-depth investigations into arrhythmic deaths (such as thorough case reviews or autopsy studies). Some find agreements52, while others suggest that death certificates may be sensitive but not specific for arrhythmic deaths24,25,26,27,28. Low specificity implies that predictions might combine arrhythmic and non-arrhythmic deaths. If we evaluate model performance solely based on death certificates, it might seem effective, but some deaths in the high-risk cohort could be non-arrhythmic and not preventable.
The limitations of any single definition of arrhythmic death mean we must validate model predictions with multiple data sources. We use three such sources. Firstly, documented ventricular arrhythmias—known contributors to sudden cardiac death—from health records in both Sweden and a US cohort. Secondly, detailed analyses of cardiac arrest causes from our hospital registry in Taiwan. Lastly, we estimate possible mortality reductions linked to defibrillators, contrasting patients with and without them to assess preventable deaths. This way, we don’t depend only on death certificates for validation and incorporate various independent datasets to isolate preventable deaths.
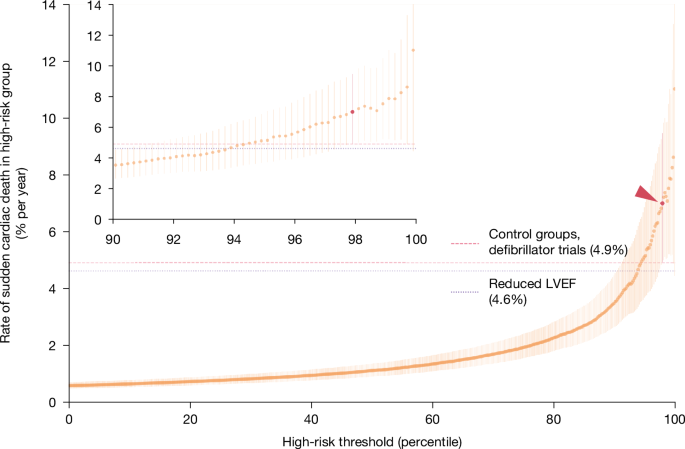
Our study emphasizes younger, healthier high-risk patients who might benefit from defibrillators since our ultimate aim is to prevent arrhythmic deaths. There isn’t a formal age cutoff for defibrillator placement8, but benefits seem to diminish with age. Older patients tend to face more complications from the procedure and have higher chances of dying from other causes. Physicians generally feel that the advantages lessen for people over 8053, and in practice, only about 10% of defibrillators in the US are implanted in that age group54. Consequently, we concentrate on ECGs performed on patients under 80 years old in our main results—74.6% of all ECGs and 25.7% of all sudden cardiac deaths. Supplementary Information replicates all main analyses in the broader cohort, revealing comparable performance even when including those over 80.
For the lockbox sample, a quick summary: the median follow-up was 2,010 days. The overall incidence of sudden cardiac death within a year post-ECG was 0.6%. Notably, 43.9% of these deaths had LVEF checked premortem, with 36.4% of those showing low LVEFs (≤ 35%). Almost half (41.2%) of sudden cardiac deaths had no identifiable risk factors during their ECG—meaning no coronary artery disease, myocardial infarction, heart failure, or prior ventricular arrhythmias; 10.0% had a recent myocardial infarction (within 40 days before the ECG, compared to a 3.3% baseline); and 7.7% had defibrillators implanted (versus a 5.4% baseline) but still suffered sudden cardiac death.
Study cohort and outcomes: USA and Taiwan
To validate our model predictions in diverse populations, we utilized two external datasets. The first is a US cohort of ECGs provided by Dandelion Health, which collects deidentified health data from various health systems across the US. We accessed 251,858 ECGs from 139,613 patients under 80, performed in 2021 and 2022, sampled at either 500 Hz (83.3%) or 250 Hz (16.7%), sourced from a GE MUSE storage system. This dataset comes from a different manufacturer and format than the Philips system used for the Swedish training data. All the 250-Hz ECGs were adjusted to 500 Hz. More details on this population are in the Supplementary Information.
The second dataset comes from a Taiwanese hospital registry through the Nightingale Open Science platform55, previously detailed56. Patients were enrolled during hospital visits after cardiac arrest (meaning, without measurable cardiac output) or after experiencing an arrest in the emergency department from 2011 to 2019. The data was collected using an Utstein-style template and linked to all patient ECGs along with those taken before the arrest. We also included ECGs from a random sample of non-arrest control patients who visited the same emergency department. ECGs taken within two days of a visit were excluded, as they could be related to the same acute event causing the arrest, which makes them less useful for prevention. The final sample includes 4,268 patients—257 arrests and 4,011 controls. These ECGs were sampled at 500 Hz and retrieved from a GE MUSE ECG storage system. Additional details are available in the Supplementary Information.
Predictive model training
Before developing the model, we surveyed literature and online platforms (like PhysioNet) to analyze deep-learning architectures for ECG waveforms. After testing various models (including convolutional networks, residual networks, transformers, and LSTMs) and hyperparameters (like the number of layers and learning rates), we settled on a 64-layer ResNet model. This comprises 32 residual blocks, each with 2 convolutional layers containing 128 filters and a kernel size of 16. We confirmed that this model performs at or above existing benchmarks—both for discernible ECG features (like QRS and QT intervals, as well as arrhythmias) and less obvious patient details (like age and cardiovascular outcomes).
The model aims to predict the likelihood of sudden cardiac death based on death certificates within a year following the ECG. This involves a multitask learning approach with three main components across different training data subsets: (i) predicting sudden cardiac death in the entire cohort (along with other outcomes); (ii) predicting sudden cardiac death versus other mortalities within a year post-ECG; and (iii) predicting reduced LVEF (≤35%) for patients with measured LVEF. Predictions were calibrated using logit, focusing on patients under 80 years old in the Swedish training set to generate the final predictions. The Supplementary Information provides further details. Predictions made in the Swedish lockbox and external validation samples weren’t adjusted at all, intended to evaluate ‘zero-shot’ performance in new datasets.
Generative model and morphing procedure
Both the generative model and the guiding predictive model are trained on individual ECG beats, segmented from a larger dataset of 10-s ECGs using standard methods. By focusing on individual beats rather than the full ECGs, we can better understand specific morphologic changes identified by the predictive model. To retrain the predictive model, we retained the same architecture and training method as those used for the 10-s ECGs. The generative model was trained using a variational auto-encoder (VAE) with a 512-dimension latent space to represent these individual beats. All outputs from this generative model and morphing procedure arise from the initial training dataset instead of the lockbox, primarily because of the comprehensive review needed which was hard to replicate within the lockbox. We consider this approach acceptable since the focus is on hypothesis generation rather than predictive accuracy.
The morphing process starts by randomly selecting 56 patient beats for the VAE to encode (this number was chosen based on computational considerations, as processing each beat took hours). These beats help explore the model’s latent space: we evaluate the gradient of predicted risk around each beat and tweak its latent vector accordingly. This adjustment creates a higher-risk vector, which is then reconstructed, resulting in a contrafactual higher-risk ECG waveform. This new vector serves as the basis for further adjustments and reconstructions, repeated until the risk of the synthetic beat reaches the 90th risk percentile. More information on this process can be found in the Supplementary Information, with the accompanying codebase available at https://github.com/alexmschubert/ECG-SCD.
Reporting summary
You can find further information about the research design in the Nature Portfolio Reporting Summary connected to this article.







